Takt ingests billions of warehouse scans from our customers every year. Every time an item is scanned in the warehouse a record is generated that includes information about the item, task, and actor who completed the task. In order to provide real-time insights to our customers, Takt ingests data from the Warehouse Management Systems (WMS), robotics, and payroll systems every 5 minutes. Once the data is received, Takt transforms the data from the source systems format to the Takt schema, assigns the transaction to a shift, and then writes the data to our database. Once the transactions from the source systems are captured, Takt enriches the data with synthetic transactions from our Virtual Kiosk, which enables tracking of indirect or “off-gun” tasks.
We set out to select a database that was easily scalable, maintainable, and secure. At Takt, we want our engineering team focused on delivering new features for our customers rather than maintaining systems. A critical step in achieving this goal is using managed services in the cloud to take on the “undifferentiated heavy lifting” so we can focus on what makes our product better.
Our MVP that we piloted with a large retailer was based on MySQL and deployed to Google Cloud SQL. In general it worked well, but we found ourselves doing many unnatural things in order to hit our performance goals. These unnatural things like creating multiple databases across instances, constantly adding read replicas, and a line of sight to using something like Vitess in order to meet our storage needs. We wanted a database that was horizontally scalable that “just worked” so we didn’t have to worry about it.
We evaluated moving just our transactions to Google Bigtable, as transactions are time series based. The issue we ran into was the various query patterns we needed to support for manipulating data. Manipulating data within Bigtable requires well defined keys and a consistent pattern for querying that data. Being an early stage startup, not sure of where our journey would take us, locking into a key structure at that time was a one way door that we didn’t feel comfortable walking through.
Enter, Google Cloud Spanner. Spanner offered a SQL interface, with a read and mutation API that worked well with Golang. It offered indexes that we could tailor to our specific algorithms needs and scale horizontally as our storage needs grew.
Today we use Google Cloud Spanner to achieve 20-30 writes per second and 30-50 reads per second across a 4.5TB database.
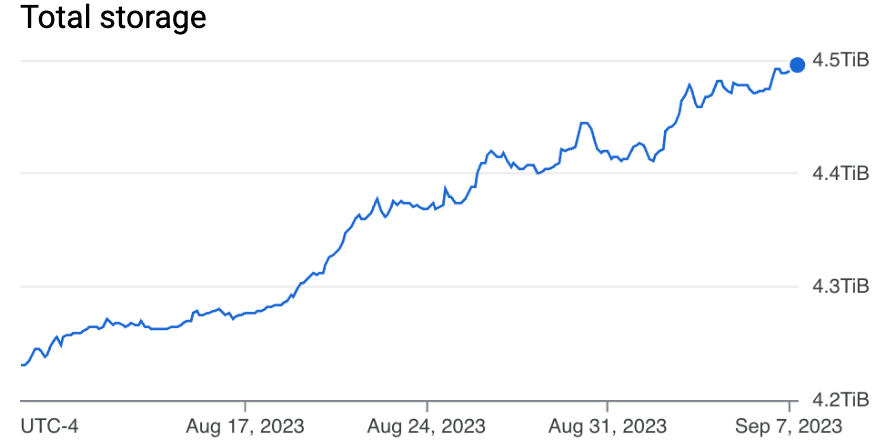
Our database reads have a sub 5ms latency on average. As our storage and query needs have increased, we simply add another node to the Spanner instance.
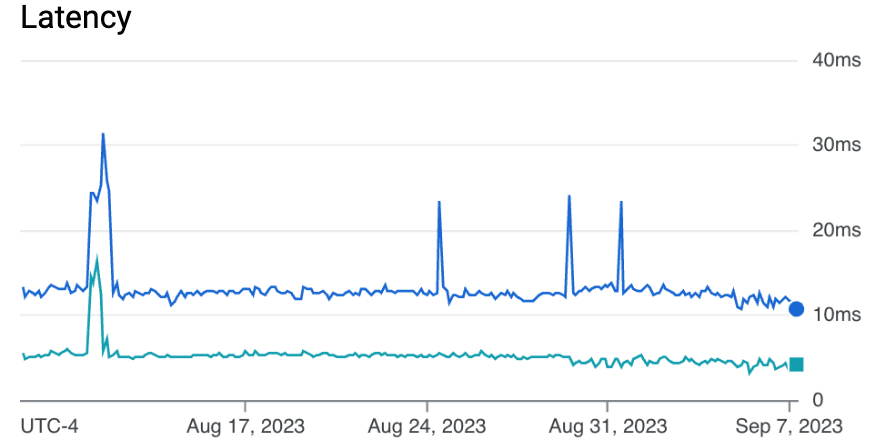
We have been using Spanner for 2 years now and have learned a lot about using Spanner to ensure performance.
- UUIDs for Primary Keys - We use UUIDs instead of incrementing ids to ensure our data is spread out across nodes and we avoid hot spots within our database.
- Nested tables work great for smaller tables - We group all of our customer configuration in nested tables which you can think of as a composite primary key. We have found this isolates performance within a customer.
- Read API over SQL - We limit our use of SQL in favor of the read API for maximum performance. All of our regular operations leverage the primary key or a secondary index for reading data. We only use SQL when we know it is a small table or backed by an index with stored columns.
One of the big knocks on Spanner is that it is “expensive” compared to some of the other database options. We have found it well worth the price. One of the ways we mitigate the cost is through Committed Use Discounts (CUDs). This significantly reduces the cost. If we were to run a database this scale on our own we would need an operations team to support the configuration, scale, and maintenance. The premium on top of a similarly sized Cloud SQL instance is well worth it for the performance and maintenance benefits.
Google Cloud Spanner plays a critical role in delivering Takt, the SaaS Warehouse Labor Management System (LMS) of the future.